UAS Information Retrieval (IR)
Soal:
1. Metode / Algoritma apa saja yang
digunakan untuk melakukan IR?
2. Bagaimana perbedaan cara kerja Precision
versus Recall, berikan contohnya.
3. Jelaskan Algoritma Web-Crawler yang
sederhana, berikan contohnya.
Jawaban
1.
Metode
/ Algoritma yang digunakan untuk melakukan IR
a. Salah satu Algoritma yang
digunakan untuk melakukan IR adalah Markov Chain, Markov
Chain adalah
sistem yang merupakan himpunan dari beberapa state
(kata) yang
berbeda. Penelitian ini berfokus besarnya ketergantungan sebuah kata dengan kata
lain sehingga jika ada sebuah frasa (pasangan kata) yang mempunyai
ketergantungan yang rendah, bisa dihilangkan salah satu atau seluruh kata
tersebut dalam kalimat. Karena pasangan kata yang mempunyai ketergantungan yang
rendah biasanya bukan merupakan kata yang penting untuk membentuk kalimat.
Proses penghilangan kata yang mempunyai nilai ketergantungan rendah tersebut
biasa disebut juga dengan ekstraksi kalimat.

Gambar.3. Markov Chain
b. Hidden Markov Model (HMM) adalah suatu rantai Markov dimana simbol keluaran atau
fungsi peluang yang menggambarkan simbol keluaran berhubungan dengan state atau transisi antar state. Observasi tiap state digambarkan secara terpisah dengan suatu fungsi probabilitas atau
fungsi densitas (probability density function,
pdf) yang
didefinisikan sebagai peluang untuk menghasilkan simbol tertentu saat terjadi
transisi antar state. Berbeda dengan Observable
Markov Model (OMM),
HMM terdiri dari serangkaian proses stokastik rangkap yang proses utamanya
tidak dapat diobservasi secara langsung (hidden) tetapi hanya dapat diobservasi
melalui set proses stokastik lain yang menghasilkan suatu deretan observasi.

Gambar 4. Hidden Markov Model
c. Algoritma Knuth-Morris-Pratt
Algoritma ini dikembangkan oleh D.E.
Knuth bersama dengan J.H Morris dan VR Pratt. Algoritma ini termasuk salah satu
algoritma primitive yang digunakan untuk mencari kesamaan pola pada string atau
deretan suatu karakter.
Pada persoalan pencocokan string umumnya
diberikan dua buah hal utama:
· Teks, string yang relative panjang yang akan menjadi bahan yang
akan dicari kecocokannya (dimisalkan panjang dari teks adalah n)
· Pattern,
string dengan panjang
relatif lebih pendek dari teks (misalkan panjang pattern adalah m, maka
m<n). Pattern akan digunakan sebagai string yang dicocokkan ke dalam
teks.
Umumnya persoalan berupa, “carilah apakah
ditemukan pattern yang diberikan pada teks tertentu”. Jawabannya bisa berupa
ada atau tidak, berapa kali ditemukan, ataupun di posisi ke berapa.

Gambar 1. Contoh pergeseran pointer pattern
pada KMP
Dasar utama dari algoritma
knuth-morris-pratt adalah untuk mereduksi pergeseran pointer pencocokan string
lebih jauh daripada harus menggesernya satu persatu layaknya yang dilakukan
pada metode pencocokan string dengan algoritma brute force.
Uniknya, berbeda dengan cara konvensional
(brute force) yang melakukan pergeseran sebanyak satu, informasi dari
pattern akan menentukan jumlah pergeseran yang relatif lebih jauh.
Keuntungan dari algoritma
Knuth-Morris-Pratt selain cepat juga sangat baik digunakan pada file berukuran
besar karena pencarian kecocokan tidak perlu kembali ke belakang pada input
teks. Namun memiliki kekurangan yakni efektifitas dari algoritma ini akan
berkurang seiring dengan bertambahnya jumlah alphabet (jenis karakter) dari teks.
2.
Perbedaan
cara kerja Precision versus Recall
a. Precision
Precision adalah: Bagian dari dokumen ter-retrieve
yang relevan, atau dapat diartikan sebagai kemiripan atau kecocokan (antara
permintaan informasi dengan jawaban terhadap apa yang diminta). Jika seseorang
mencari informasi di sebuah sistem, dan sistem menawarkan beberapa dokumen,
maka kepersisan ini sebenarnya juga adalah relevansi. Artinya, seberapa persis
atau cocok dokumen tersebut untuk keperluan pencari informasi, bergantung pada
seberapa relevan dokumen tersebut bagi si pencari.
precision adalah proporsi jumlah dokumen yang
ditemukan dan dianggap relevan untuk kebutuhan si pencari informasi.
Rumusnya:
Jumlah
dokumen relevan yang ditemukan
Jumlah dokumen yang ditemukan
Contoh Precision

b. Recall
Recall adalah: bagian dari dokumen relevan yang te-retrieve,
atau Recall adalah proporsi jumlah dokumen yang dapat
ditemukan-kembali oleh sebuah proses pencarian di sistem IR.
Rumusnya:
Jumlah dokumen
relevan yang ditemukan
Jumlah semua dokumen relevan di dalam koleksi
Contoh Recall
3.
Jelaskan
Algoritma Web-Crawler yang sederhana
Crawling adalah proses pengambilan sejumlah besar halaman
Web dengan cepat ke dalam suatu
tempat penyimpanan lokal dan mengindeksnya berdasar sejumlah kata kunci. Idealnya
(untuk ukuran saat ini) program akan mengambil puluhan ribu halaman Web per
detik. Crawler adalah salah satu komponen utama dalam sebuah Search Engine,
sebagai aplikasi Information Retrieval modern. Web Crawler atau yang dikenal juga dengan istilah web spider bertugas untuk
mengumpulkan semua informasi yang ada di dalam halaman web. Web crawler bekerja secara
otomatis dengan cara memberikan sejumlah alamat website untuk dikunjungi serta
menyimpan semua informasi yang terkandung didalamnya. Setiap kali web crawler mengunjungi
sebuah website, maka dia akan mendata semua link yang ada dihalaman yang dikunjunginya
itu untuk kemudian di kunjungi lagi satu persatu.
Algoritma
SIMPLE_CRAWLER berikut merupakan
versi yang sudah disederhanakan hanya untuk menunjukkan mekanisme dasar proses
crawling. Algoritma ini pada dasarnya melakukan suatu kunjungan graf (Graph
Traversing).
•
Input
:
S0
dari URL (sering disebut sebagai seeds)
•
Output:
D dan E,
masing-masing adalah tempat penyimpanan dokumen dan link yang saling
berkorespondensi
Algoritma
ini disesuaikan dengan tiga pola stategi yang digunakan orang untuk menemukan
file yang dicari pada suatu mesin pencari.
a)
Breadth-first
Search
Teknik
breadth-first adalah first-in-first-out (FIFO) di mana nod pertama yang dimasukkan
akan dikeluarkan dahulu. Kebanyakan web crawler menggunakan teknik melebar
dahulu untuk proses crawling karena algoritma ini bersifat mudah dan tidak
kompleks. Semua URL pada tingkatan pertama akan dijelajah dahulu sebelum
menjelajah kepada tingkatan seterusnya. Nilai heuristik tidak digunakan untuk
menentukan URL yang mana dikehendaki dijelejah seterusnya.
Breadth-first
search adalah algoritma
yang melakukan pencarian secara melebar yang mengunjungi simpul secara preorder
yaitu mengunjungi suatu tautan kemudian mengunjungi semua tautan yang berdekatan
dengan tautan tersebut terlebih dahulu. Selanjutnya, tautan yang belum
dikunjungi dan berdekatan dengan tautan-tautan yang tadi dikunjungi , demikian
seterusnya.
Jika graf
berbentuk pohon berakar, maka semua tautan pada tingkat d dikunjungi
lebih dahulu sebelum tautan-tautan pada tingkat d+1. Algoritma ini
memerlukan sebuah antrian q untuk menyimpan tautan yang telah
dikunjungi. Tautan-tautan ini diperlukan sebagai acuan untuk mengunjungi tautan-tautan
lain yang berkaitan dan berdekatan dengannya. Tiap tautan yang telah dikunjungi
masuk ke dalam antrian hanya satu kali. Algoritma ini juga membutuhkan table
Boolean untuk menyimpan tautan yang telah dikunjungi sehingga tidak ada tautan yang
dikunjungi lebih dari satu kali.
Terdapat tiga langkah yang dilakukan oleh WebCrawler ini
ketika mengunjungi dokumen, yaitu menandai bahwa suatu dokumen telah dikunjungi,
mengenali link yang terdapat pada dokumen tersebut, kemudian isinya didaftarkan
pada daftar indeks. Pada akhirnya, WebCrawler akan menampilkan file yang
paling banyak berkaitan dengan kata kunci.
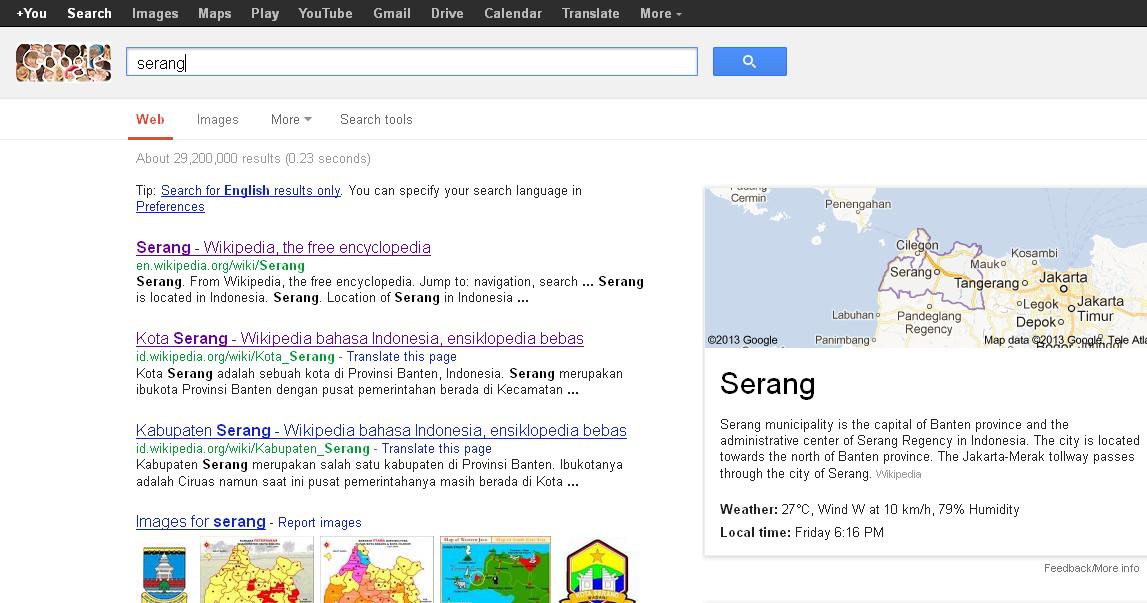
Contoh hasil pencarian dengan WebCrawler Kata kunci :
"serang"
Hasil pencarian :

Algoritma BFS yang diterapkan pada WebCrawler ini adalah
mendaftarkan setiap link yang ada dan menyimpannya dalam data base kemudian mengunjunginya
satu persatu sambil mencatat link yang berhubungan.
b) Depth-first Search
Depth-first search (DFS) melakukan pencarian secara preorder.
Mengunjungi sub suatu tautan sebelum tautan yang berdekatan. Berkaitan dengan mesin
pencari, DFS ini cenderung mengindeks dokumen berdasarkan suatu link.
Algoritma DFS yang diterapkan pada mesin pencari dalam melakukan
pengindeksan adalah mengunjungi suatu server kemudian menyimpan semua link yang berhubungan dengan server
tersebut baru kemudian mengunjungi server lain.
c) Teknik best-first
Teknik best-first adalah
algoritma pencarian yang menggunakan heuristik untuk menyusun URL dan menentukan
nod yang mana ditemukan terlebih dahulu. URL yang berkaitan akan disusun pada
bagian depan suatu query, jika
URL yang kurang berkaitan akan disusun pada bagian belakang suatu query untuk ditampilkan.
Taraf URL ini ditentukan oleh fungsi rangking (rank function).
URL yang baru dimasukkan ke dalam daftar query akan kehilangan peluang untuk dijelajah
sekiranya ia mempunyai nilai tertinggi (ceiling value).
d)
Teknik
Backlink-count
Teknik backlink-count adalah
teknik di mana laman web yang mempunyai nilai bilangan hubungan yang terbanyak
berhubung dengannya akan ditampilkan terlebih
dahulu. Oleh sebab itu, laman web yang seterusnya ditampilkan adalah laman web
yang paling berkaitan dengan laman web yang telah dimuat.
e)
Teknik
Batch-page-rank
Web
crawler akan memuat sejumlah K laman web dan semua laman web tersebut
akan dinilai dengan menggunakan nilai pagerank.
Sejumlah K laman
web yang akan dimuat seterusnya adalah laman web yang mempunyai nilai pagerank yang
tertinggi. Nilai pagerank
ini akan dihitung setiap kali terdapat URL yang baru di download.
Teknik batch-pagerank adalah
lebih baik jika berbanding dengan teknik backlink-count.
f)
Teknik
Partial-pagerank
Teknik partial-pagerank adalah
sama seperti teknik batch-pagerank,
tetapi ketika proses pemberian nilai pagerank,
satu nilai pagerank sementara
diberikan kepada laman web yang baru dimuat. Nilai pagerank sementara
ini adalah sama dengan total normalized
rankings suatu laman web yang berhubung dengannya. Oleh karena itu,
laman web yang terkini dijumpai dapat crawl
oleh web
crawler dengan secepat mungkin. Laman web yang di download adalah
laman web yang nilai partial
pagerank yang tertinggi.
g)
Teknik
On-line Page Important Computation (OPIC)
Dalam teknik OPIC, semua laman web
permulaan mempunyai nilai cash
yang sama. Setiap kali laman web tertentu crawl oleh web crawler,
nilai cashnya
akan diberikan kepada laman web yang berhubungan dengannya. Laman web yang
belum dijelajahi oleh web
crawler akan mempunyai jumlah nilai cash daripada laman web
yang berhubungan dengannya. Strategi ini hampir sama dengan pagerank,
tetapi pengiraannya adalah tidak diulangi. Oleh sebab itu, teknik dengan menggunakan
strategi ini adalah lebih pantas.
Secara
umum terdapat 3 pola strategi yang dilakukan oleh user mesin pencari untuk menemukan
file yang sesuai dengan kata kunci yaitu strictly depth-first strategy,
extreme breath-first strategy dan partially breath-first pattern. Metode
strictly depth-first strategy berarti pengguna mengamati tiap link hasil
dari mesin pencari mulai dari atas, dan memutuskan segera untuk membuka dokumen
atau tidak. Metode extreme breath-first strategy berarti pengguna
melihat keseluruhan link daftar hasil pencarian kemudian memilih link yang
mengacu ke dokumen yang paling sesuai lalu mengunjungi link tersebut.
Sekali-kali pengguna juga melihat kembali daftar hasil pencarian lalu
mengunjungi ulang beberapa link yang menurut dia berkaitan. Metode partially
breath-first pattern merupakan metode campuran dimana pengguna melihat beberapa
link baru memutuskan link mana yang akan dibuka.
Berdasarkan
penelitian yang dilakukan oleh Kerstin Klockner, Nadine Wirshum, Anthony
Jameson pada makalahnya yang berjudul “Depth- and Breadth-First Processing of
Search Result” dapat disimpulkan bahwa pengguna cenderung melakukan pencarian
secara strictly depth-first strategy. Yaitu melihat suatu link yang
paling atas dari hasil pencarian kemudian mengaksesnya dan terus menelusuri
link yang terdapat pada document tersebut yang berkaitan dengan kata kunci yang
dicari. Sehingga agar pencarian lebih efektif perlu ada penyesuaian dengan
algoritma mesin pencari. Algoritma yang menurut kami paling sesuai adalah
algoritma BFS pada mesin pencari yang akan menampilkan daftar file yang paling
dekat relefansinya dengan kata kunci. Metode sama dengan WebCrawler yaitu
mengunjungi setiap server, mencatat link file dan memasukkannya ke dalam basis
data. Sehingga file yang paling relevan ditempatkan di bagian paling atas
daftar hasil pencarian. Kelebihan metode baru ini bagi pengguna adalah pengguna
akan dapat langsung melihat file yang paling relevan pada bagian atas.
Information Retrieval
Information Retrieval


Komentar
Posting Komentar